




Leading flexible vision tokenizers achieve state-of-the-art quality at an extreme cost, relying on parameter-heavy backbones and slow, multi-step generative decoders. We depart from this complex, spatial-token paradigm and introduce a simple, lightweight, and fast channel-wise flexible-length tokenizer. Our method treats each latent channel as a visual token, enabling a parameter-efficient CNN–Transformer hybrid backbone. Employing a stochastic tail-dropping paradigm during training naturally forces channels to organize by semantic importance.
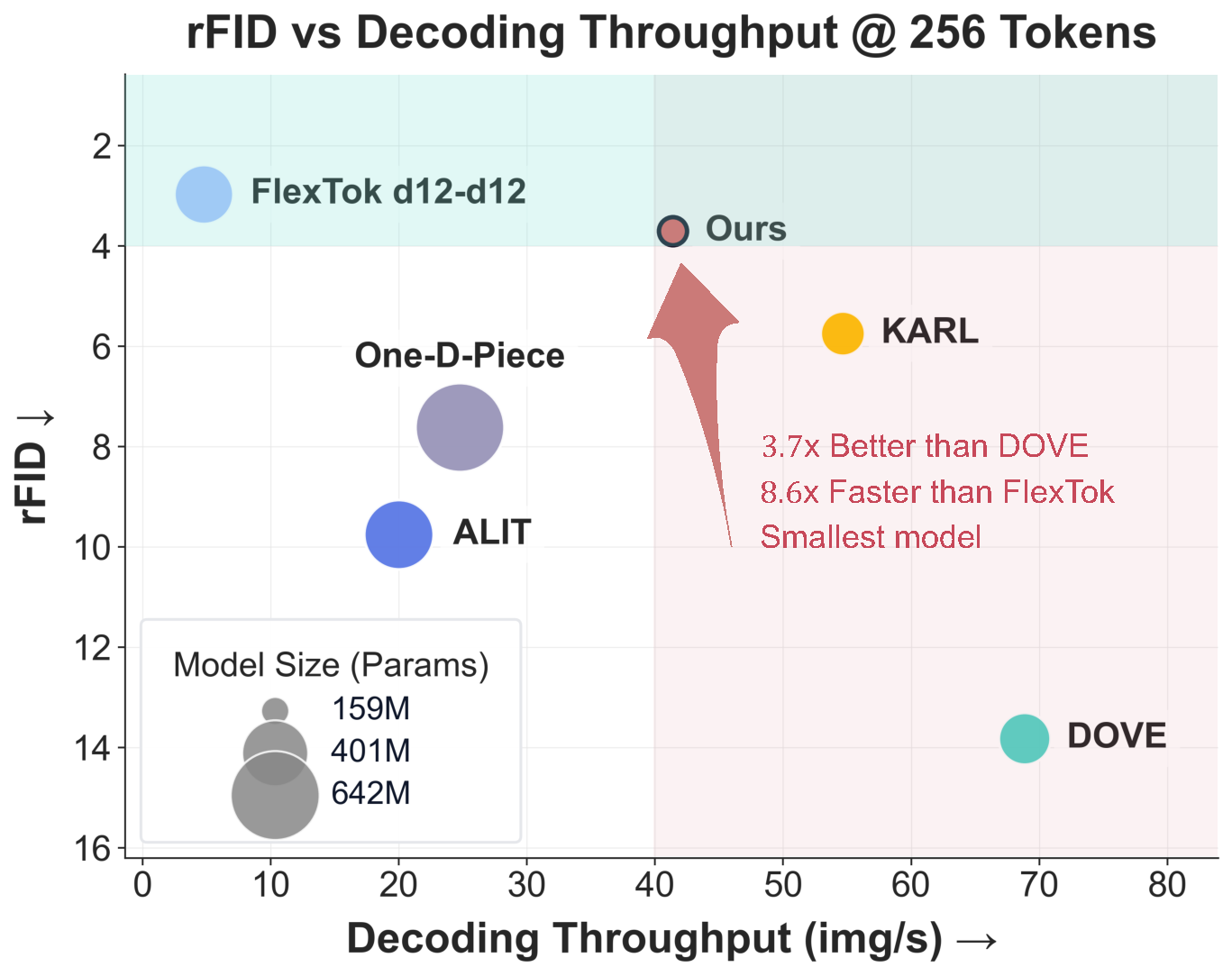
This allows for flexible compression at inference by simply retaining the first k channels, and naturally enables variable-length autoregressive image generation. We validate on ImageNet, demonstrating consistent quality across diverse token budgets. Our model achieves state-of-the-art perceptual quality (rFID 2.92) while being 8.6× faster in decoding and 2.1× smaller (159M params) than the next-best alternative — establishing channel-wise tokenization as a powerful and practical paradigm for efficient visual representation.
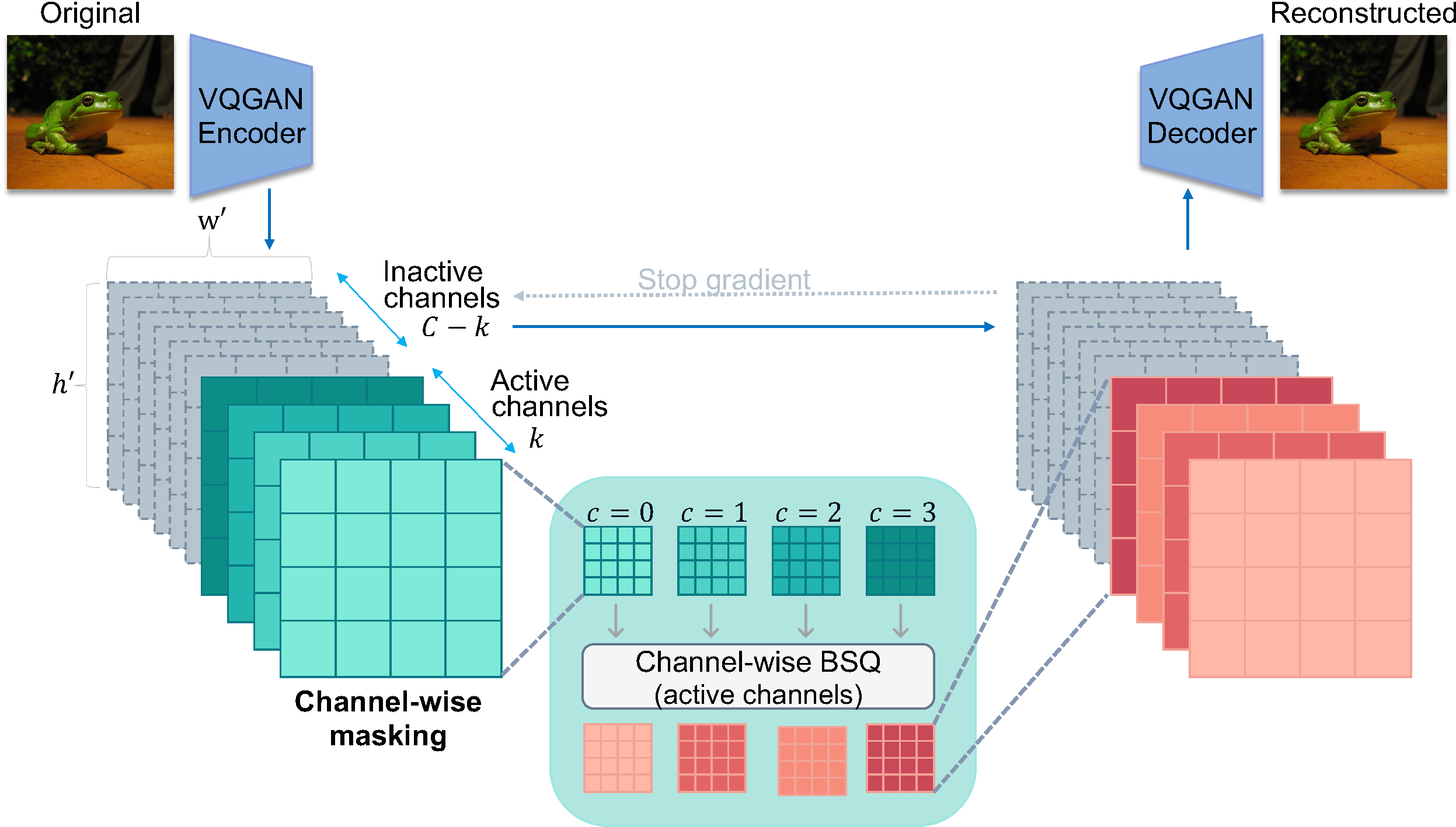
The encoder compresses an input image into a latent z ∈ ℝC×h×w. During training, we stochastically retain only the first k channels (teal), stop gradients through inactive channels (gray), and independently quantize each active channel with Binary Spherical Quantization (BSQ). At inference, varying k gives flexible compression without retraining: 32 channels for coarse structure, 512 for full fidelity. This gives us a quality–bitrate knob at inference with no additional cost.

Because channels are ordered by importance, image generation is naturally progressive, one channel at a time, coarse to fine. Stop early for a quick sketch, or run to completion for full detail. This opens the door to interactive, anytime-stop autoregressive image generation. At just 32 tokens, generation runs at 7.9× the speed, completing a full image in 0.48s.
* AR generation uses a tokenizer trained on ImageNet-100k with a maximum token budget of 256, a separate setting from the main reconstruction results.



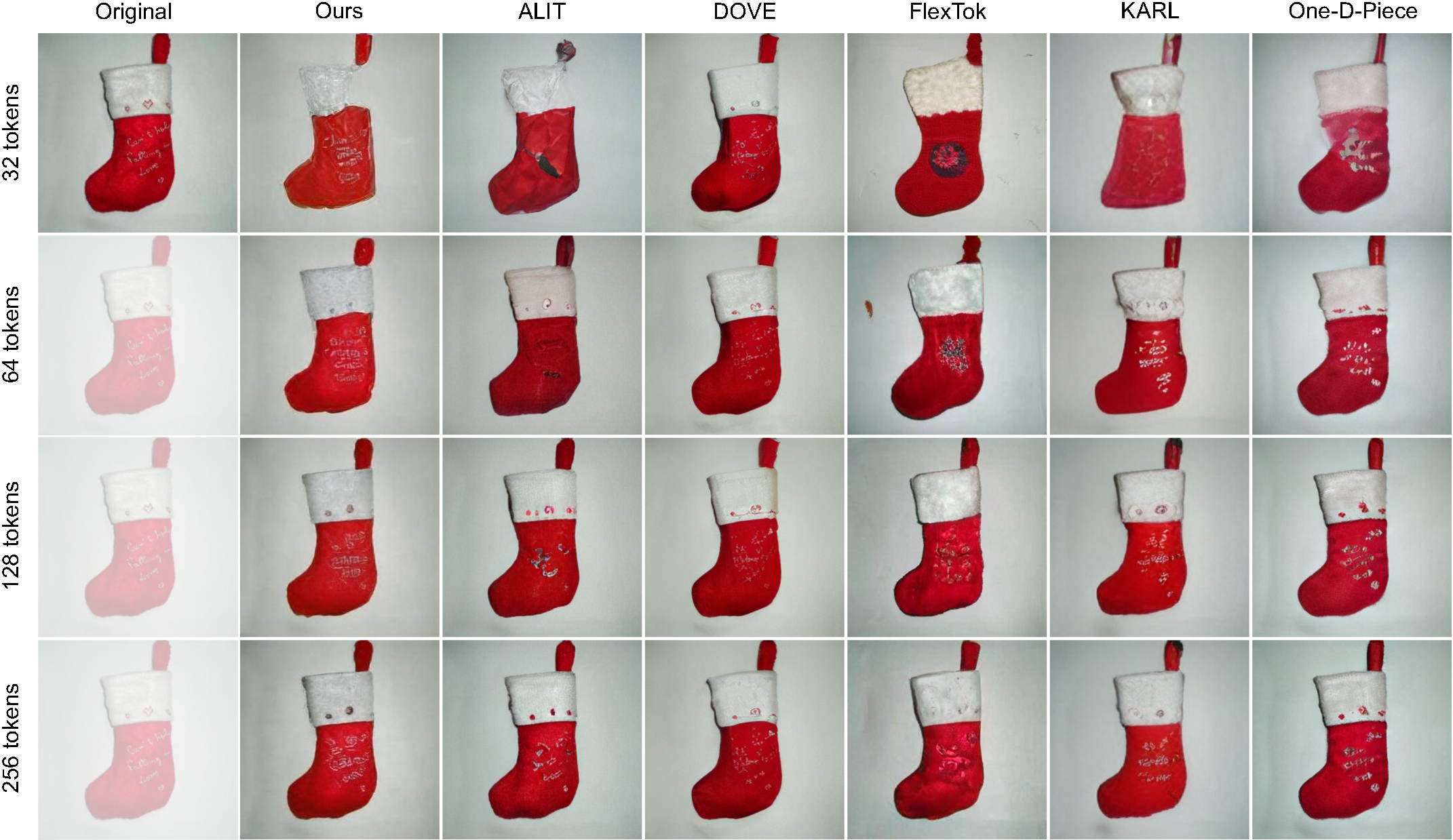
Prefix masking during training induces a coarse-to-fine ordering across channels, capturing global structure in early channels followed by progressively finer-grained detail. Without this masking, coherent reconstructions only appear at high token budgets.



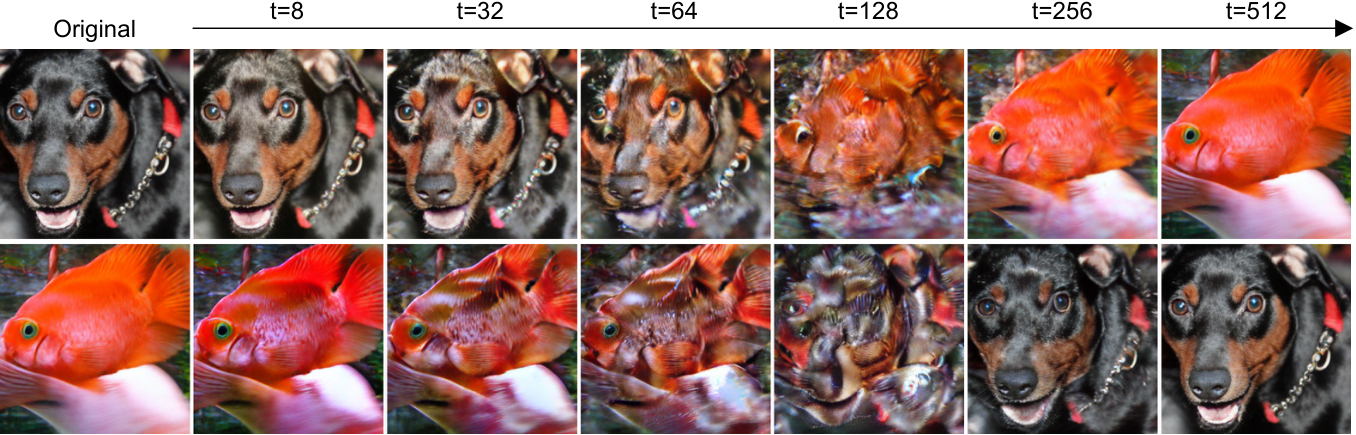

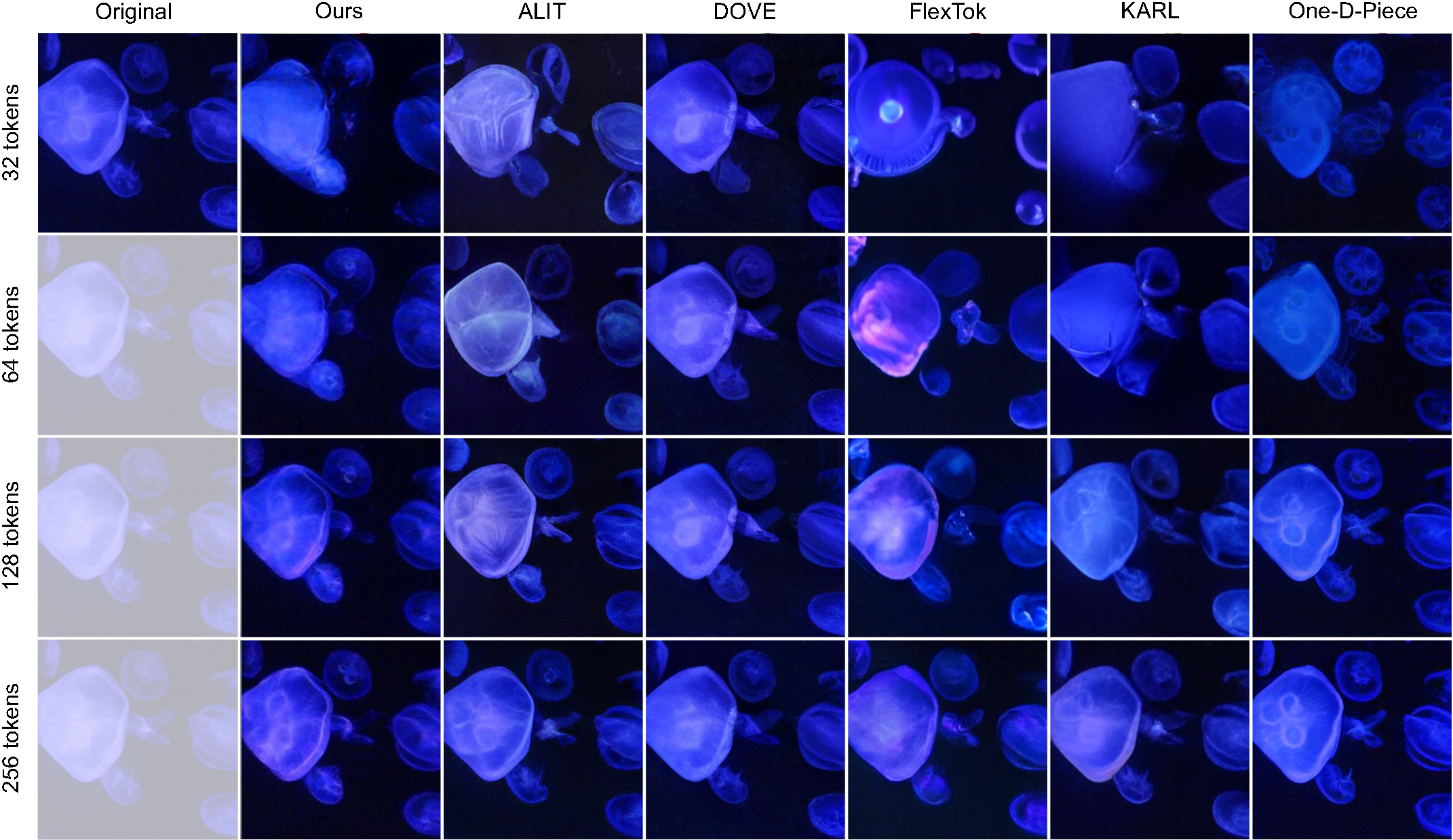
Swapping channels between two images at inference reveals the semantic hierarchy encoded by ChannelTok. Up to 64 tokens, global structure is preserved with only subtle stylistic transfer. Beyond 64 tokens, the foreground object itself begins to metamorphose, reflecting the finer semantic content carried by later channels.
If you find our work useful, please cite:
@misc{paul2026channeltok,
title = {ChannelTok: Efficient Flexible-Length Vision Tokenization},
author = {Paul, Sukriti and Bansal, Arpit and Goldstein, Tom},
journal = {arXiv preprint},
year = {2026},
}